
Geospatial Data Structures: Advantages and Disadvantages

Geospatial data structures are critical for managing, processing, and storing geospatial data in an efficient and organized manner. There are several popular geospatial data structures such as R-Tree, Quad-Tree, Uniform Grid, Space-Filling Curves, and GeoHashing, each with its own strengths and weaknesses. In this article, we will take an in-depth look at the pros and cons of each of these data structures, providing you with the information you need to make an informed decision when choosing the right geospatial data structure for your needs.
R-Tree
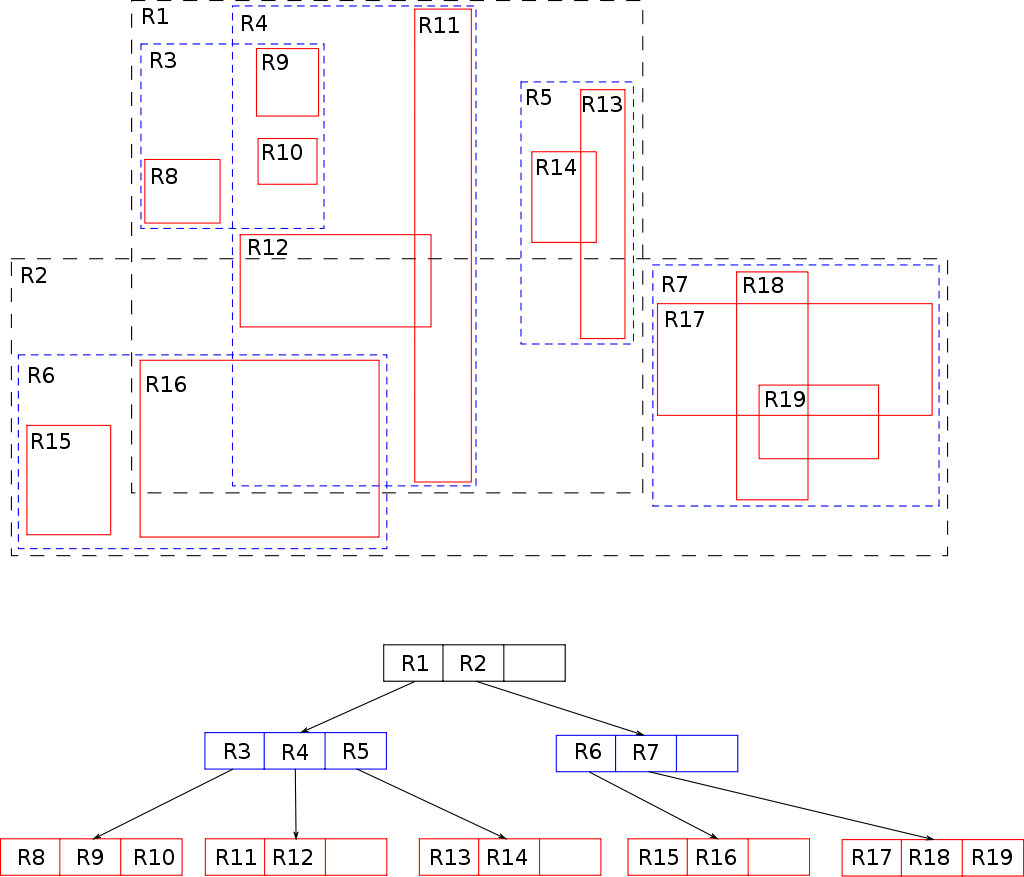
Advantages of Using R-Trees
R-Trees have several advantages over other geospatial data structures. One of the primary advantages of R-Trees is their ability to handle large amounts of data. The structure of an R-Tree allows for quick indexing and retrieval of data, even when dealing with massive amounts of information. R-Trees are also capable of handling both static and dynamic data, making them an ideal choice for real-time applications.
Additionally, R-Trees are efficient at handling data with high dimensions, making them a popular choice for geospatial applications. The tree structure of an R-Tree allows for efficient storage and retrieval of data, even when dealing with complex geospatial data.
Disadvantages of Using R-Trees
While R-Trees have several advantages, they also have some disadvantages. One of the primary disadvantages of R-Trees is their sensitivity to data distribution. If the data is not evenly distributed, the tree may become unbalanced, leading to inefficient retrieval and indexing. Additionally, R-Trees are not well-suited for handling data with high degrees of overlap, as this can result in the creation of large numbers of overlapping nodes in the tree.
Another disadvantage of R-Trees is their complexity. The structure of an R-Tree can be difficult to understand and implement, making it challenging for developers who are unfamiliar with the data structure. Additionally, the algorithms used to manage and maintain R-Trees can be complex, requiring a significant amount of time and effort to develop and implement.
Quad-Tree

Advantages of Using Quad-Tree
The main advantage of Quad-Trees is their ability to provide fast querying times even when working with large datasets. This makes them ideal for use in applications where you need to quickly retrieve data based on its spatial location, such as in GIS applications. Additionally, Quad-Trees are also well suited for working with data that is primarily two-dimensional, as they are optimized for working with this type of data.
Disadvantages of Using Quad-Tree
One of the main disadvantages of Quad-Trees is that they may not be as efficient when working with data that has a large number of dimensions. This is because the tree structure of a Quad-Tree is optimized for working with two-dimensional data, and may not be as efficient when dealing with data that has more dimensions.
Uniform Grid
Uniform Grids are a type of data structure used to efficiently store and retrieve spatial data. They are similar to Quad-Trees in that they allow for fast querying of data based on its spatial location. However, unlike Quad-Trees, Uniform Grids are specifically designed to work with data that is evenly spaced, making them ideal for use in applications where the data is evenly distributed.
Advantages of Using Uniform Grid
The main advantage of Uniform Grids is their ability to provide fast querying times even when working with large datasets. This makes them ideal for use in applications where you need to quickly retrieve data based on its spatial location, such as in GIS applications. Additionally, Uniform Grids are also well suited for working with data that is evenly spaced, as they are optimized for working with this type of data.
Disadvantages of Using Uniform Grid
However, the Uniform Grids also has some disadvantages. For example, it is not well suited for data that is distributed unevenly, as cells in areas with a high density of data will become cluttered, while cells in areas with a low density of data will be mostly empty. This can lead to inefficient use of memory and computational resources, which can negatively impact the performance of the system.
Space-Filling Curves
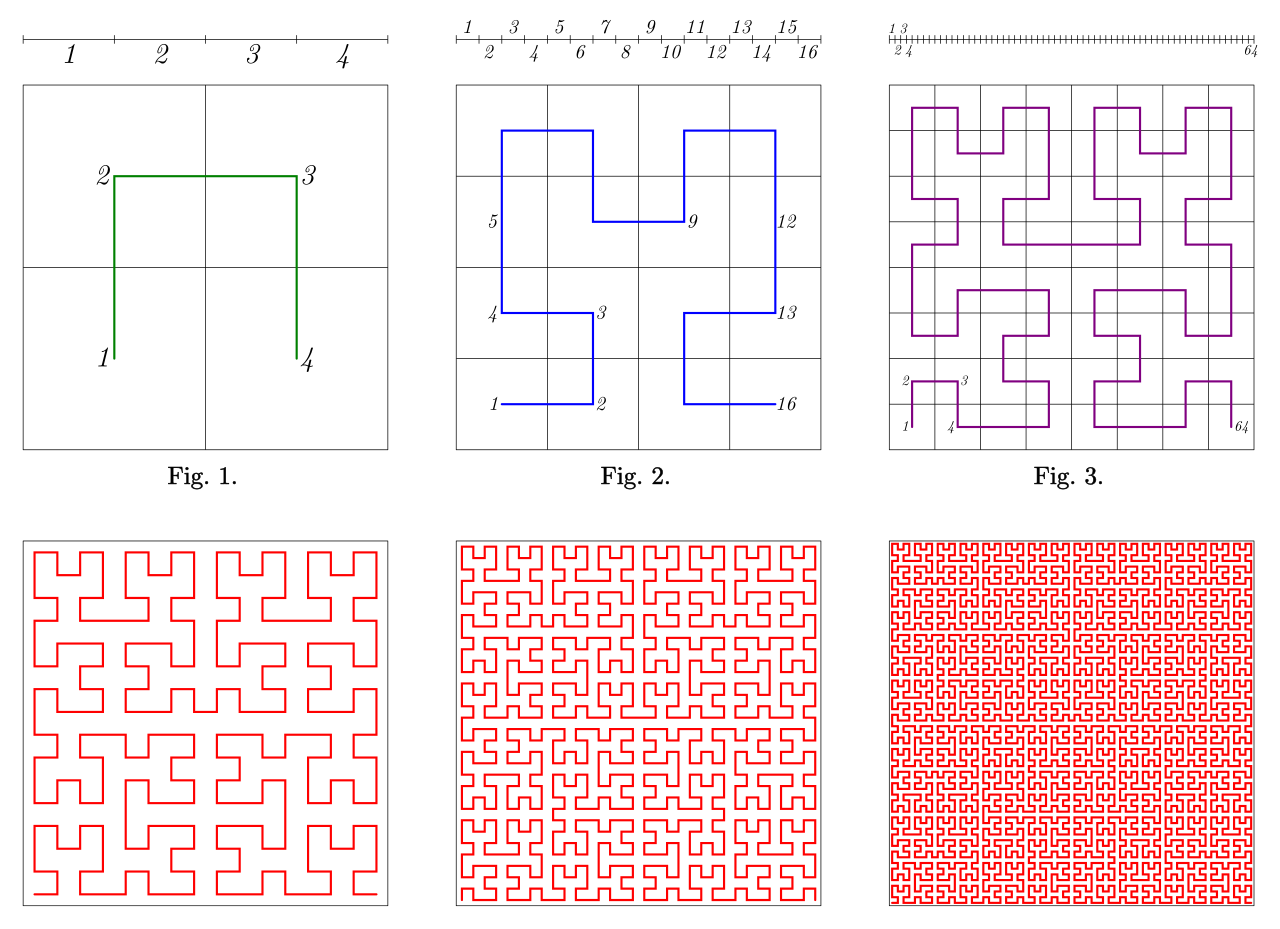
Advantages of Using Space-Filling Curves
One of the main advantages of this approach is that it allows for efficient and effective access to the data, as well as for efficient visualizations. Additionally, the use of a Space-filling curves allows for the data to be stored in a more compact form, which can reduce memory and computational requirements.
Disadvantages of Using Space-Filling Curves
However, Space-filling curves can also be complex to implement, and may require significant computational resources, which can limit their practical applications. Additionally, they may not always provide the best representation of the data, as the curve may not accurately capture the underlying structure or relationships within the data set.
GeoHashing
GeoHashing is a method of organizing geospatial data that is based on dividing a geographic region into a set of cells, and encoding the location of each point into a hash value that corresponds to a specific cell. This allows for the data to be efficiently organized, searched, and visualized.
Advantages of Using GeoHashing
One of the advantages of this method is that it provides a simple and efficient way to encode and access the data, while also allowing for easy visualization of the data. Additionally, the use of a hash value can reduce memory and computational requirements, as well as provide a way to quickly search and retrieve data.
Disadvantages of Using GeoHashing
However, GeoHashing can also have some limitations. For example, the hash values can be affected by the size and shape of the cells, and may not provide the most accurate representation of the data. Additionally, the encoding process may be complex and may require significant computational resources, which can limit its practical applications.
Choosing the Right Geospatial Data Structure
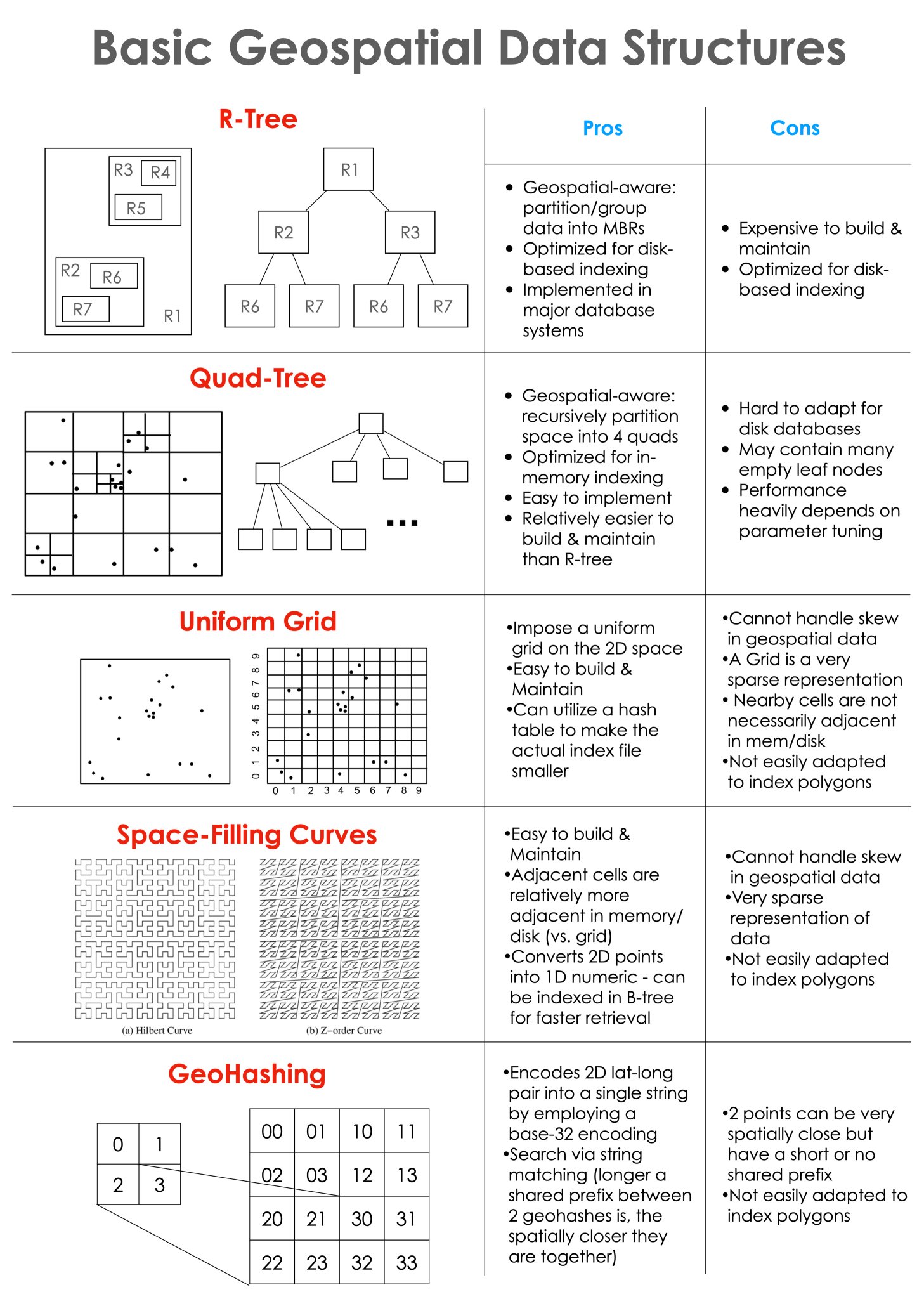
Geospatial data structures are essential tools for managing and organizing geographic information in a manner that makes it easy to access and analyze. However, the wide range of options available can make it difficult to decide which structure is best for a given project. The five data structures discussed in this article, R-Tree, Quad-Tree, Uniform Grid, Space-Filling Curves, and GeoHashing, each have their own advantages and disadvantages.
Small and Simple Projects
For small, simple projects, a Quad-Tree or a Uniform Grid may be a good choice. These structures are easy to implement, understand, and provide fast query times for simple geometric shapes and small datasets.
Large and Complex
For large, complex projects, the R-Tree is the preferred choice. This structure is designed for high-dimensional data and can handle large datasets with ease. It also supports fast searching and retrieving of data, making it well-suited for complex applications that require the efficient storage and retrieval of large amounts of data.
Another option for complex projects is the Space-Filling Curve or GeoHashing. These structures provide a unique way to organize and access data based on their position in space, making them ideal for large-scale data management and analysis. However, they are more difficult to understand and implement, making them a better choice for experienced users or teams.
Conclusion
In conclusion, the choice of geospatial data structure will depend on the size and complexity of the project, as well as the skills of the user or team. Regardless of the structure chosen, it is important to understand the strengths and limitations of each data structure to ensure that the right choice is made for the specific project needs.